
這篇在講什麼
這篇用學員的實際當機畫面當案例,講四件事:logs_2.sqlite 這個本機 log 資料庫是什麼,Codex 打不開時怎麼安全處理,怎麼設定每 3 到 5 天的自動巡檢,以及怎麼讓任務和心血不跟著工具故障一起不見。所有技術說法的依據是 OpenAI Codex GitHub repo 裡的相近 issue 與原始碼,不是官方公告。
- 你每天靠 Codex Desktop 工作,某天它突然整個打不開,怎麼重開都進不去。
- 你更新到最新版、甚至重裝過,還是擔心同樣狀況哪天又來。
- 你聽過 logs_2.sqlite、WAL、VACUUM 這些字,卻不知道該不該動、會不會越弄越糟。
- 你最怕的是工具壞掉,連帶把這幾天的任務和工作現場一起賠進去。
- 看懂 logs_2.sqlite 是什麼、不該拿它當什麼用,知道它為什麼可能拖累 Codex 啟動。
- 一套保守的當機處理順序,先備份、先檢查,能不亂刪就不亂刪。
- 一段可以直接貼給 Codex 的巡檢自動化指令,預設只巡檢、不自動清。
- 一個讓任務心血不跟著工具一起消失的工作習慣。
先講這次發生什麼事
學員的 Codex Desktop 怎麼重開都進不去,畫面顯示發生錯誤,並出現 signal=SIGKILL、config.toml、更新 Codex、重新載入等建議。實際處理時,更新到最新版本還是沒有恢復,最後靠重新安裝才重新啟動。

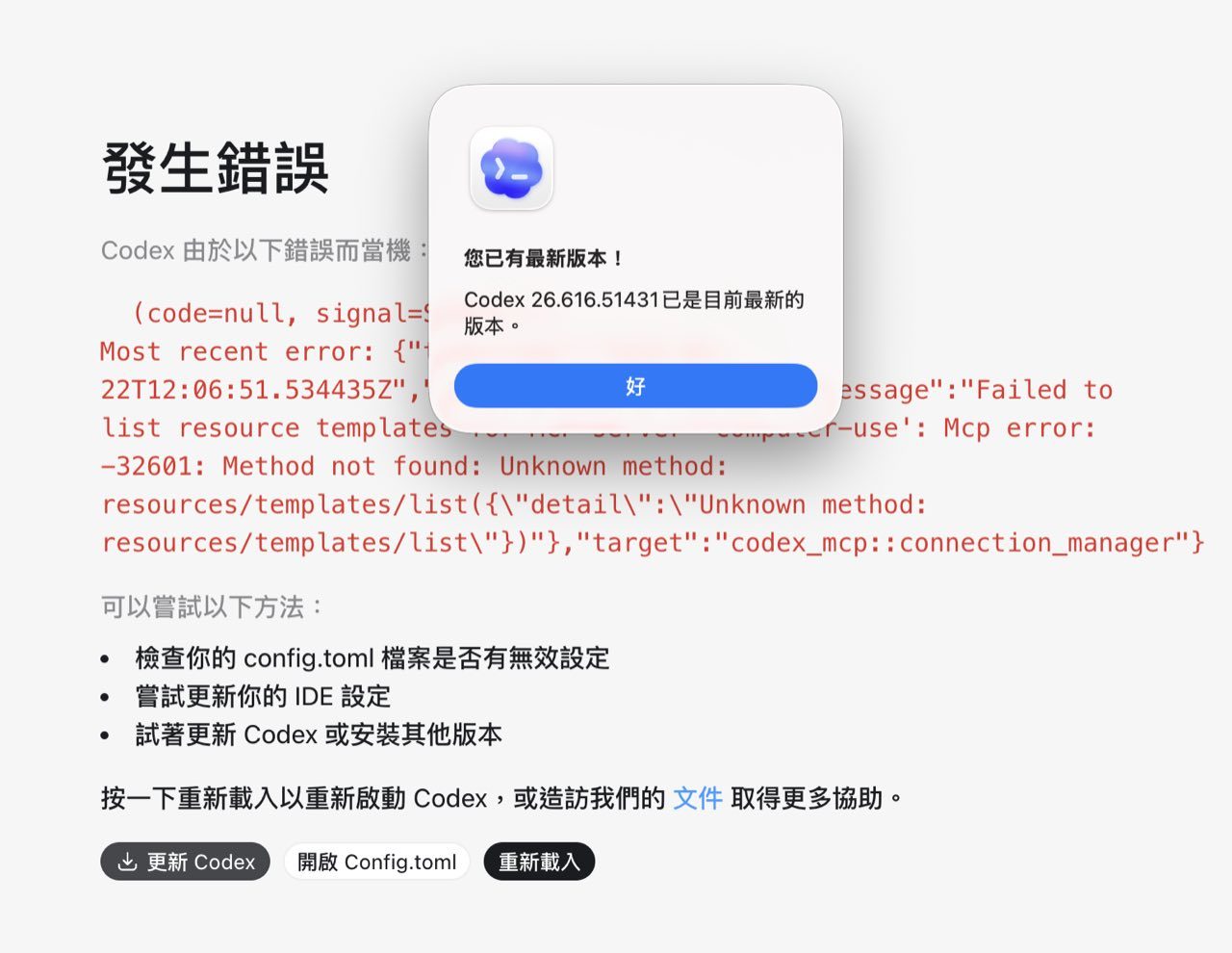

先把問題定位講準
這件事很容易被講成「OpenAI 官方說 Codex 有這個 bug」。正確的說法要保守一點。
OpenAI Codex 的 GitHub repo 裡,有多個相近 issue 指向 logs_2.sqlite 過大、corrupt log DB、WAL 持續成長,或高量 TRACE log 寫入等風險。這些是社群回報與維護者討論,不是官網公告。
logs_2.sqlite 是值得優先檢查的可能原因之一。它不等於所有 Codex 當機的唯一答案。當機可能還有別的成因,這篇先處理這個有跡可循、又能自己安全檢查的部分。
把定位講準,後面的處理才不會走偏。我們要做的是「先檢查這個高機率又可自查的地方」,而不是斷定「當機一定是它害的」。完整 issue 連結放在文末「參考的 issue 和原始碼」。
logs_2.sqlite 到底在寫什麼?
logs_2.sqlite 是 Codex Desktop 在本機使用的 SQLite log 資料庫。可以把它理解成本機運作紀錄,記錄程式跑起來留下的診斷資料。它不是你的正式工作日誌,也不是技能包、記憶庫或成品資料夾。
時間、等級、target、錯誤訊息、tracing span、連線或工具執行狀態,以及程式運作需要留下的診斷資料。
它不是你的正式筆記,也不適合當成長期保存工作成果的地方。任務結論、交付物和技能包,應該另外存成自己的檔案。
log 可能包含本機路徑、錯誤片段、工具呼叫摘要或工作環境資訊。可以清理與備份,不建議拿原始資料庫到處傳。
查 repo 時看到幾個相近回報:有人把 logs_2.sqlite* 移走後,Codex 會自己重建 log 資料庫;也有人回報 WAL 檔、TRACE 等級 log 或資料庫異常導致問題。這代表它有它的脾氣,值得當成一個會長大的本機資料庫來照顧,不該放著讓它無限膨脹。
出事時怎麼處理
先看你的狀況,這裡分兩條路。手動能力比較強、或電腦上同時裝了 Claude Code,走路線一的保守完整流程。如果你還是新手,走路線二的簡單三步就好。
路線一:有操作能力,或裝了 Claude Code
如果你手動能力比較強,或同時也裝了 Claude Code,可以請 Claude Code 照下面這套保守順序處理。目標是先保留現場,再讓 Codex 重建可以重建的 log 狀態。每一步都建立在「備份在前、動手在後」之上。
先完全關閉 Codex,避免資料庫正在寫入時動它。
備份 ~/.codex/logs_2.sqlite、logs_2.sqlite-wal、logs_2.sqlite-shm。三個檔案都先留一份,再處理。
檢查主檔、WAL、SHM 大小,並執行 SQLite quick_check。如果資料庫健康又不大,只回報狀態,不要硬清。
如果主檔過大、WAL 過大、筆數異常或 quick_check 不正常,先確認完整備份存在,再保留最近 48 小時 log,執行 checkpoint、VACUUM 與 PRAGMA optimize。
如果連安全清理都無法執行,可把 logs_2.sqlite* 移到備份資料夾,讓 Codex 重新建立 log 資料庫。這一步仍要先備份,不要直接刪除。
如果試過仍無法啟動,才考慮解除安裝再重裝。重裝後第一件事,就是做下一段的自動巡檢。
路線二:新手就照這三步
如果你還不熟,不用糾結那些指令,記住三步就好。
直接重新安裝 Codex。先接受一件事:本機任務有可能跟著消失,這種情況下也只能這樣,先把 Codex 救回來再說。
重啟成功後,先別急著開新任務。一開新任務,log 會繼續寫進去,很可能很快又爆滿、又當掉。所以重啟後的第一件事,是立刻把日誌清乾淨。
日誌清乾淨後,建立下一段的自動巡查。之後它會幫你固定做健康檢查,就不太會再走到重裝這一步。

平常怎麼預防:請 Codex 幫自己做健康巡檢
與其等當機才處理,平常固定巡檢更省事。如果你每天都開 Codex,我會建議每 3 到 5 天巡一次。我自己偏向週二和週五早上各跑一次。偶爾使用的人,一週一次也夠。
每 3 到 5 天檢查一次,我偏向週二、週五。門檻可設主檔大於 300MB、WAL 大於 100MB、log 筆數大於 120000,或 quick_check 不正常才維護。
一週一次即可。重點是固定做健康檢查,不是每天清。發現異常時,先確認備份存在再處理。
新開一個 Codex 對話框,直接貼這段
這段指令把上面的安全線寫死在裡面:只檢查不亂清,達門檻先回報並產出維護交接指令,遇到不確定狀況立刻停手。貼之前把路徑裡的使用者名稱換成你自己的,或直接叫 Codex 用目前電腦的路徑替換。
/Users/你的使用者名稱/。請不要自己亂改隱藏資料夾,也不要把整個 .codex 資料夾刪掉。
怎麼避免任務和心血一起不見
這次真正值得記住的,是不要把 Codex 的本機狀態當成唯一保存位置。工具會更新、會壞、會重裝。自己的資料要靠自己的習慣保住。我平常靠三件事。
每個任務收尾時,把做了什麼、產出在哪裡、遇到什麼問題、下一步是什麼,寫成自己的工作日誌。
文章、圖片、簡報、程式碼、提示詞、報告,都要落成檔案,存進自己看得到的位置,不要只留在對話裡。
反覆會用的流程,整理成技能包或 SOP。這樣 Codex 出事時,Claude、其他 Agent 或下一台電腦也讀得懂、接得上。
把這三件事做起來,就算哪天 Codex 整個 down 掉,也只是換一個 AI 工具接著讀資料,工作脈絡還在,不會從零開始。
三十秒收尾
- Codex Desktop 打不開、更新無效、最後重裝,重裝後第一步先檢查
logs_2.sqlite。 - 查證依據是 OpenAI Codex GitHub repo 的相近 issue 與原始碼。它是值得優先檢查的可能原因之一,當機還可能有別的成因。
- 處理分兩條路:有操作能力或裝了 Claude Code,走保守流程(先關 Codex、備份三個 log 檔、檢查 quick_check、健康別硬清、異常才在備份後維護,遇到鎖檔或權限錯誤立刻停手);新手就重新安裝、重啟後先清日誌別急著開新任務、再建立自動巡查。
- 平常設每 3 到 5 天的自動巡檢,預設只巡檢。達門檻時先輸出維護交接指令,等 Codex 關閉後再處理。
- 任務結束寫工作日誌、成品落成檔案、好操作沉澱成技能包。
這篇參考的 issue 和原始碼
下面是這篇的查證依據,全部來自 OpenAI Codex 的 GitHub repo,不是 OpenAI 官網公告。這些 issue 指向 log SQLite 資料庫過大、WAL 異常、corrupt log DB 或高量 TRACE log 寫入等風險,支撐「logs_2.sqlite 值得優先檢查」這個判斷。
- openai/codex issue #27741:回報 Codex Desktop 因
logs_2.sqlite長大而啟動失敗,移走 log DB 後可重建。 - openai/codex issue #24001:回報 corrupt
logs_2.sqlite造成問題,重新命名 log DB 後可恢復。 - openai/codex issue #29463:回報高量 TRACE websocket log 寫進
logs_2.sqlite。 - openai/codex issue #28997:討論 WAL 成長,以及不要直接刪 live WAL 的風險。
- Codex 原始碼 config/mod.rs:可看到 Codex home、sqlite home、log dir 等本機路徑概念。
這篇最重要的一句話
log 可以清,任務和心血要自己保存。把 log 巡檢、自動健康檢查、工作日誌和技能包沉澱做起來,工具壞掉就只是工具壞掉,不會連你的工作脈絡一起消失。
每個月兩場免費講座。
點我加入 Line 社群 ↗